使用goner/otel/meter实现应用指标监控
引言
在现代微服务架构和分布式系统中,可观测性(Observability)已经成为确保系统稳定性和性能的关键因素。可观测性通常由三大支柱组成:日志(Logs)、指标(Metrics)和追踪(Traces)。本文将重点介绍其中的"指标"部分,探讨如何使用Gone框架的goner/otel/meter组件来高效地收集、管理和可视化应用指标数据。
通过构建一个健壮的指标监控系统,开发团队可以实现:
- 实时监控应用性能和健康状态
- 提前发现潜在问题,防患于未然
- 建立基于数据的决策机制,优化系统性能
- 有效进行容量规划和资源分配
技术栈介绍
Gone框架
Gone是一个轻量级的Go语言依赖注入框架,设计理念类似于Java的Spring框架。它通过依赖注入的方式组织代码,使应用更加模块化、可维护和可测试。Gone框架的核心优势在于其简洁而强大的组件管理机制,可以轻松地将各种功能模块集成到应用中。
OpenTelemetry (OTel)
OpenTelemetry是一个开源的可观测性框架,它提供了一套标准化的API、库和代理,用于收集和处理遥测数据(日志、指标和追踪)。OpenTelemetry的出现解决了可观测性工具碎片化的问题,使开发者可以使用统一的API收集遥测数据,然后将这些数据发送到任何后端分析工具。
goner/otel/meter是Gone框架对OpenTelemetry指标收集功能的封装,它使得在Gone应用中集成OpenTelemetry变得非常简单。
Prometheus
Prometheus是一个开源的监控和警报系统,专为高度动态的云原生环境设计。它通过以下特性脱颖而出:
- 多维数据模型:每个时间序列由指标名称和键值对标签定义
- 强大的查询语言PromQL:支持复杂的数据聚合和转换
- 无需依赖存储:支持本地存储和远程存储
- 基于HTTP的Pull模式采集:简化了网络配置
- 支持Push模式的网关:用于短期任务的监控
- 丰富的可视化集成:原生支持Grafana等工具
在本教程中,我们将使用Prometheus作为指标数据的存储和查询后端。
快速开始
1. 准备工作
首先,我们需要安装Gone框架的命令行工具gonectl。它能帮助我们快速创建和管理Gone项目:
go install github.com/gone-io/gonectl@latest
gonectl工具功能强大,提供了项目脚手架、代码生成和项目管理等功能,大大简化了使用Gone框架的开发流程。确保您的$GOPATH/bin已添加到系统路径中,这样才能在命令行中直接使用gonectl命令。
2. 创建示例项目
使用gonectl创建一个基于otel/meter/prometheus模板的项目。这个模板已经包含了所有必要的监控组件配置:
gonectl create -t otel/meter/prometheus meter-prometheus
执行这个命令后,gonectl会自动创建一个名为meter-prometheus的项目目录,并生成所有必要的文件和配置。这个过程中,gonectl主要完成了以下工作:
- 创建基本的项目结构
- 自动生成Gone框架所需的依赖注入配置文件
- 配置OpenTelemetry和Prometheus相关组件
- 添加示例控制器和API端点
- 创建Docker Compose配置,便于启动Prometheus服务
3. 启动应用
进入项目目录,运行以下命令启动应用服务:
go run ./cmd
当你看到类似于Server started at :8080的输出时,表示应用已经成功启动。此时,Gone框架已经自动完成了以下工作:
- 初始化了所有注册的组件
- 配置了OpenTelemetry指标收集器
- 启动了一个Gin HTTP服务器
- 注册了
/metrics端点,用于暴露Prometheus格式的指标数据 - 启动了我们定义的API端点(如
/hello)
4. 启动Prometheus监控服务
项目中已经包含了Prometheus的配置文件,使用Docker启动Prometheus服务:
docker compose up -d
这个命令会启动一个Prometheus容器,并使用项目中的prometheus.yml配置文件。Prometheus服务启动后,它会按照配置定期从我们的应用的/metrics端点拉取指标数据。
Prometheus的工作原理是定期"刮取"(scrape)目标服务的指标数据,然后存储在时间序列数据库中。这种Pull模式的采集方式有几个优点:
- 简化了防火墙配置(只需要Prometheus能够访问目标服务)
- 使得Prometheus能够检测到目标服务的健康状态
- 减轻了目标服务的负担(由Prometheus控制采集频率)
5. 验证监控效果
现在,让我们来验证监控系统是否正常工作:
- 多次访问示例接口,产生一些监控数据:
curl http://localhost:8080/hello
每次调用这个接口,我们的应用都会增加一个名为api.counter的指标计数器。
- 查看原始指标数据:
curl http://localhost:8080/metrics
这个命令会显示当前应用暴露的所有指标数据,格式符合Prometheus的数据格式规范。你应该能看到类似下面的输出:
# HELP api_counter API调用的次数
# TYPE api_counter counter
api_counter{} 5 1620847200000
这个输出表明:
api_counter是一个计数器类型的指标- 它的描述是"API调用的次数"
- 当前值是5(表示API已被调用5次)
- 时间戳是1620847200000(这是一个Unix毫秒时间戳)
- 在Prometheus控制台查看可视化的指标数据:
- 打开Prometheus界面:http://localhost:9090/graph
- 在查询框中输入:
api_counter_total - 点击"执行"按钮,你将看到类似下图的监控数据展示:
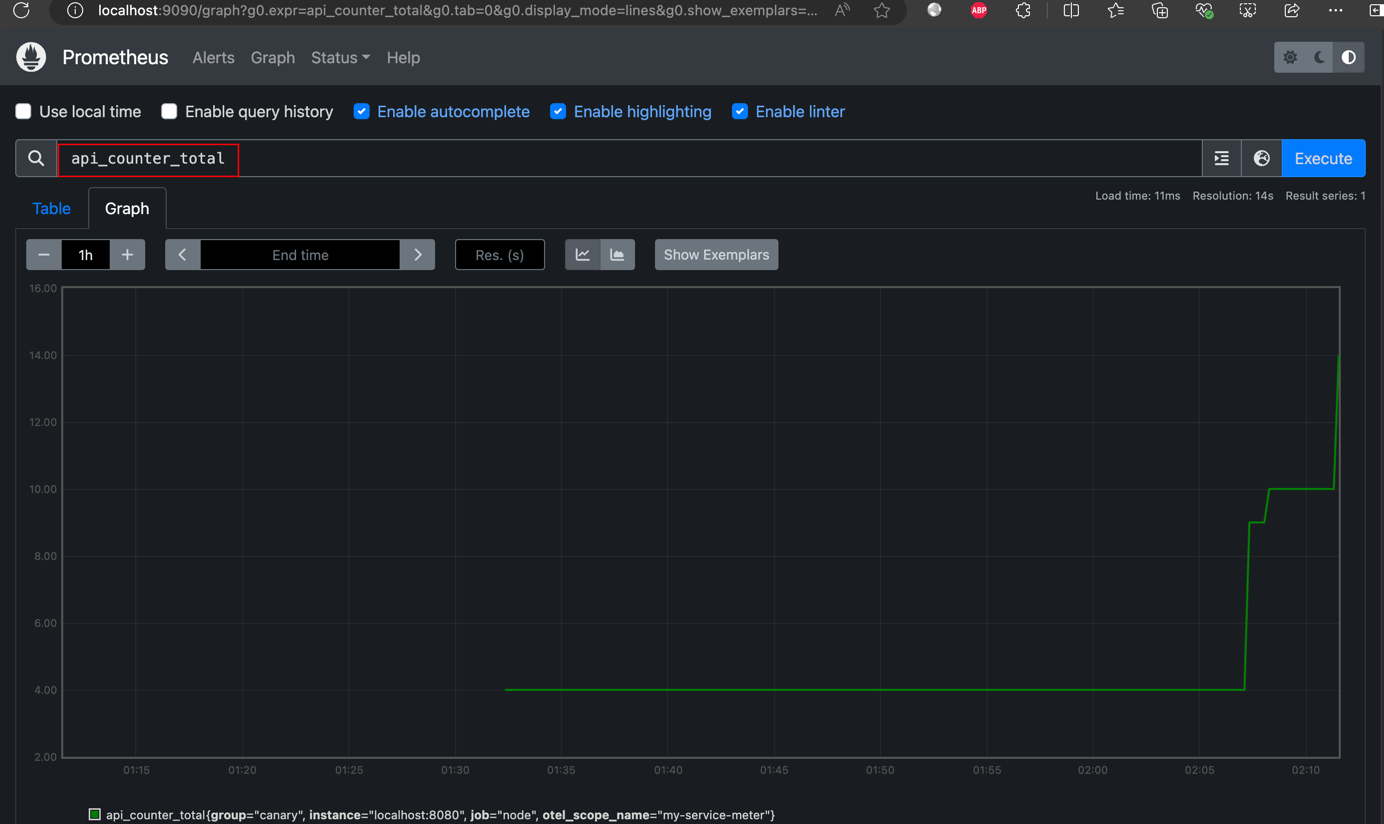
在Prometheus的Web界面中,你可以:
- 查看指标随时间的变化趋势
- 使用PromQL进行复杂的查询和数据分析
- 创建自定义的监控面板
- 设置告警规则(需要额外配置AlertManager)
代码详解
让我们深入了解这个监控系统的实现原理和核心代码。
项目结构
.
├── cmd
│ ├── import.gone.go # 自动生成的组件导入文件
│ └── server.go # 应用入口文件
├── controller
│ ├── ctr.go # API接口定义和指标收集逻辑
│ └── init.gone.go # 控制器初始化文件
├── docker-compose.yaml # Docker配置文件
├── prometheus.yml # Prometheus配置文件
├── init.gone.go
└── module.load.go # Gone模块加载配置
这种项目结构遵循了Gone框架的最佳实践,将不同功能模块清晰地分离。其中:
cmd目录包含应用的入口点和自动生成的组件导入文件controller目录包含API控制器和路由定义- 根目录包含Gone框架的配置文件和Prometheus相关配置
核心组件说明
项目使用了goner/otel/meter/prometheus/gin组件,它提供了一个完整的指标监控解决方案,包括:
- 自动创建一个HTTP服务(默认端口8080)
- 提供
/metrics接口用于暴露符合Prometheus格式的监控指标 - 集成了OpenTelemetry指标收集和Prometheus导出功能
- 基于Gin框架实现Web服务和路由管理
这个组件实际上是一个组合组件,它包含了以下功能模块:
goner/otel/meter/prometheus:Prometheus指标收集器和导出器goner/otel/meter:OpenTelemetry指标管理核心功能goner/otel:OpenTelemetry基础功能和配置goner/gin:基于Gin的Web服务框架
通过Gone框架的依赖注入机制,这些组件被自动组合在一起,形成了一个完整的监控解决方案。
指标类型详解
在OpenTelemetry中,有四种基本的指标类型:
-
Counter(计数器):只增不减的累计值,适用于记录事件发生的次数、请求数等。
- 示例:API调用次数、错误发生次数
-
Gauge(仪表盘):可增可减的瞬时值,适用于记录当前状态。
- 示例:当前活跃连接数、当前内存使用量
-
Histogram(直方图):记录观测值的分布情况,适用于分析数据的分布特征。
- 示例:请求响应时间分布、文件大小分布
-
Summary(摘要):类似于直方图,但直接计算分位数。
- 示例:响应时间的95分位数、99分位数
在本示例中,我们使用了最简单的Counter类型来记录API调用次数。
指标收集示例
在controller/ctr.go中,我们定义了一个简单的计数器指标:
package controller
import (
"github.com/gin-gonic/gin"
"github.com/gone-io/gone/v2"
"github.com/gone-io/goner/g"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/metric"
)
type ctr struct {
gone.Flag
r g.IRoutes `gone:"*"` // 通过依赖注入获取路由组件
}
func (c *ctr) Mount() (err g.MountError) {
// 创建一个名为"my-service-meter"的指标收集器
var meter = otel.Meter("my-service-meter")
// 定义一个计数器类型的指标
apiCounter, err := meter.Int64Counter(
"api.counter", // 指标名称
metric.WithDescription("API调用的次数"), // 指标描述
metric.WithUnit("{次}"), // 计量单位
)
if err != nil {
return gone.ToErrorWithMsg(err, "创建api.counter失败")
}
// 注册HTTP接口,每次访问时增加计数器
c.r.GET("/hello", func(ctx *gin.Context) string {
apiCounter.Add(ctx, 1) // 计数器加1
return "hello, world"
})
return
}
这段代码展示了如何:
-
创建指标收集器(Meter):使用
otel.Meter("my-service-meter")创建一个名为"my-service-meter"的指标收集器。指标收集器是创建和管理指标的入口点。 -
定义指标(Metric):使用
meter.Int64Counter创建一个名为"api.counter"的64位整数计数器。我们还为这个指标添加了描述和单位信息,这些信息会在Prometheus界面中显示,帮助用户理解这个指标的含义。 -
记录指标数据:在API处理函数中,使用
apiCounter.Add(ctx, 1)来增加计数器的值。每次访问/hello接口时,计数器的值都会增加1。 -
注册路由:使用
c.r.GET方法注册一个HTTP GET路由,当访问/hello路径时,会执行我们定义的处理函数。
通过这种方式,我们可以轻松地监控API的调用次数,从而了解应用的使用情况。
指标标签(Labels)的使用
在实际应用中,我们通常需要为指标添加标签(Labels),以便更细粒度地分析数据。例如,我们可以为API调用计数器添加"method"和"path"标签,以区分不同API的调用情况:
// 定义指标
apiCounter, err := meter.Int64Counter(
"api.counter",
metric.WithDescription("API调用的次数"),
metric.WithUnit("{次}"),
)
// 注册HTTP接口
c.r.GET("/hello", func(ctx *gin.Context) string {
// 带标签的指标记录
apiCounter.Add(ctx, 1, metric.WithAttributes(
attribute.String("method", "GET"),
attribute.String("path", "/hello"),
))
return "hello, world"
})
c.r.POST("/data", func(ctx *gin.Context) string {
// 使用不同的标签值
apiCounter.Add(ctx, 1, metric.WithAttributes(
attribute.String("method", "POST"),
attribute.String("path", "/data"),
))
return "data received"
})
这样,我们就可以在Prometheus中分别查询不同API的调用次数,例如:
api_counter_total{method="GET", path="/hello"}api_counter_total{method="POST", path="/data"}
监控数据采集配置
Prometheus的配置(prometheus.yml)也很简单:
scrape_configs:
- job_name: 'node'
scrape_interval: 5s # 每5秒采集一次数据
static_configs:
- targets: ['localhost:8080']
labels:
group: 'canary'
这个配置告诉Prometheus:
- 创建一个名为"node"的采集任务(job)
- 每5秒从
localhost:8080(我们的应用)拉取一次指标数据 - 为采集到的所有指标添加一个
group="canary"的标签
Prometheus会自动将这些配置应用到采集过程中,并将采集到的数据存储在其时间序列数据库中。
高级功能
使用Gauge监控系统资源
除了计数器外,我们还可以使用Gauge(仪表盘)类型的指标来监控系统资源的使用情况:
// 创建内存使用量指标
memoryGauge, _ := meter.Float64ObservableGauge(
"system.memory.usage",
metric.WithDescription("系统内存使用量"),
metric.WithUnit("MB"),
)
// 注册观察函数,定期更新指标值
meter.RegisterCallback(
func(ctx context.Context, o metric.Observer) error {
var m runtime.MemStats
runtime.ReadMemStats(&m)
o.ObserveFloat64(memoryGauge, float64(m.Alloc)/1024/1024) // 转换为MB
return nil
},
memoryGauge,
)
这段代码创建了一个可观察的Gauge指标,用于监控应用的内存使用量。通过注册回调函数,我们可以定期读取系统内存状态,并更新指标值。
使用Histogram监控请求响应时间
我们还可以使用Histogram(直方图)类型的指标来监控请求的响应时间分布:
// 创建响应时间直方图
responseTimeHistogram, _ := meter.Int64Histogram(
"api.response.time",
metric.WithDescription("API响应时间"),
metric.WithUnit("ms"),
)
// 创建中间件,记录请求处理时间
func MetricsMiddleware(apiCounter metric.Int64Counter, responseTimeHistogram metric.Int64Histogram) gin.HandlerFunc {
return func(c *gin.Context) {
start := time.Now()
// 处理请求
c.Next()
// 记录响应时间
duration := time.Since(start).Milliseconds()
responseTimeHistogram.Record(c, duration,
metric.WithAttributes(
attribute.String("path", c.Request.URL.Path),
attribute.Int("status", c.Writer.Status()),
),
)
// 记录请求计数
apiCounter.Add(c, 1,
metric.WithAttributes(
attribute.String("path", c.Request.URL.Path),
attribute.Int("status", c.Writer.Status()),
),
)
}
}
这段代码创建了一个Gin中间件,用于记录每个请求的处理时间,并将其记录为直方图指标。通过这种方式,我们可以分析API的性能特征,例如响应时间的分布、中位数、95分位数等。
使用Grafana构建可视化仪表盘
虽然Prometheus自带了基本的可视化功能,但在实际应用中,我们通常会使用Grafana来构建更丰富、更美观的监控仪表盘。Grafana可以连接多种数据源,包括Prometheus,并提供强大的可视化和告警功能。
要集成Grafana,我们可以在docker-compose.yaml中添加Grafana服务:
services:
prometheus:
image: prom/prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
grafana:
image: grafana/grafana
ports:
- "3000:3000"
volumes:
- grafana-storage:/var/lib/grafana
depends_on:
- prometheus
volumes:
grafana-storage:
然后,我们可以访问Grafana界面( http://localhost:3000 ),配置Prometheus数据源,并创建自定义仪表盘。
最佳实践
指标命名规范
良好的指标命名规范可以使监控系统更易于使用和维护。一般来说,我们应该遵循这些原则:
- 使用点分隔的命名空间:例如
app.api.counter - 在名称中包含度量类型:例如
api.request.count、api.response.time - 使用有意义的前缀:例如
app、system、db - 保持一致性:在整个应用中使用相同的命名模式
避免过度使用标签
虽然标签可以提供更细粒度的数据分析,但过度使用标签可能会导致性能问题。每个标签组合都会创建一个新的时间序列,这会增加Prometheus的内存和CPU使用量。因此,我们应该:
- 只使用必要的标签
- 避免使用高基数的标签(如用户ID、请求ID等)
- 限制标签值的数量
集成告警系统
监控系统的最终目的是及时发现问题,并采取相应的措施。Prometheus提供了强大的告警功能,可以基于指标数据触发告警。我们可以配置AlertManager来处理这些告警,并将它们发送到不同的通知渠道(如邮件、Slack、PagerDuty等)。
总结
通过本文,我们学习了如何使用Gone框架的goner/otel/meter组件,结合Prometheus和OpenTelemetry技术栈,实现应用的指标监控系统。这种监控系统具有以下优点:
- 标准化:基于OpenTelemetry标准,与生态系统兼容
- 可扩展:支持多种指标类型和复杂的数据分析
- 低侵入性:通过简单的API调用即可实现指标收集
- 高性能:对应用性能的影响极小
在实际应用中,我们可以根据需求扩展这个基础系统,添加更多的指标、构建更丰富的仪表盘,以及集成更完善的告警系统。通过这些努力,我们可以建立一个全面、高效的应用监控系统,提高应用的可观测性和可靠性。